RISC V는 University of California, Berkeley에서 개발한 명령어 집합 아키텍처입니다. RISC의 개념은 대부분의 컴퓨터 프로그램에서 대부분의 프로세서 명령을 사용하지 않는다는 사실에 의해 동기가 부여되었습니다. 따라서 불필요한 디코딩 논리가 설계 내에서 활용되고 있었습니다. 프로세서 , 더 많은 전력과 면적을 소모합니다. 명령어 세트를 줄이고 레지스터 리소스에 더 많이 투자하려면 RISC V 프로세서 구현되었습니다.
이 기술은 완전히 오픈 소스이며 무료이기 때문에 많은 기술 대기업과 신생 기업이 주목했습니다. 대부분의 프로세서 유형은 라이선스 계약을 통해 사용할 수 있지만 이러한 유형의 프로세서에서는 사용할 수 없습니다. 누구나 새로운 프로세서 디자인을 만들 수 있습니다. 따라서 이 기사에서는 RISC V 프로세서의 작동 및 응용 프로그램의 개요에 대해 설명합니다.
RISC V 프로세서란 무엇입니까?
RISC V 프로세서에서 RISC라는 용어는 컴퓨터 명령을 거의 실행하지 않는 '축소된 명령 집합 컴퓨터'를 의미하는 반면 'V'는 5세대를 의미합니다. 의 확립된 원칙을 기반으로 하는 오픈 소스 하드웨어 ISA(명령어 집합 아키텍처)입니다. 위험 .
다른 ISA 디자인과 달리 이 ISA는 오픈 소스 라이선스로 사용할 수 있습니다. 따라서 많은 제조 회사에서 오픈 소스 운영 체제와 함께 RISC-V 하드웨어를 발표하고 제공했습니다.
이것은 새로운 아키텍처이며 개방형, 비제한적 및 무료 라이선스로 제공됩니다. 이 프로세서는 칩 및 장치 제조업체 산업에서 광범위한 지원을 받고 있습니다. 따라서 주로 많은 응용 프로그램에서 사용할 수 있도록 자유롭게 확장 및 사용자 정의할 수 있도록 설계되었습니다.
RISC V 연혁
RISC는 버클리 캘리포니아 대학교의 David Patterson 교수가 1980년경에 발명했습니다. David 교수와 John Hennessy 교수는 “Computer Organization and Design”과 “Computer Architecture at Stanford University”라는 두 권의 책에 그들의 노력을 투고했습니다. 그래서 그들은 ACM A.M.을 받았습니다. 2017년 튜링상 수상.
1980년부터 2010년까지 RISC 5세대 개발 연구가 시작되어 마침내 Risk 5로 발음되는 RISC-V로 확인되었습니다.
RISC V 아키텍처 및 작업
RV12 RISC V 아키텍처는 아래와 같습니다. RV12는 임베디드 분야에서 사용되는 단일 코어 RV32I 및 RV64I 호환 RISC CPU로 고도로 구성할 수 있습니다. RV12는 또한 산업 표준 RISC-V 명령어 세트에 따라 32비트 또는 64비트 CPU 제품군에 속합니다.
RV12는 명령과 데이터 메모리에 동시에 액세스하기 위해 Harvard 아키텍처를 실행합니다. 또한 6단계 파이프라인이 포함되어 있어 실행과 메모리 액세스 간의 겹침을 최적화하여 효율성을 개선합니다. 이 아키텍처에는 주로 분기 예측, 데이터 캐시, 디버그 단위, 명령 캐시 및 선택적 승수 또는 분배기 단위가 포함됩니다.
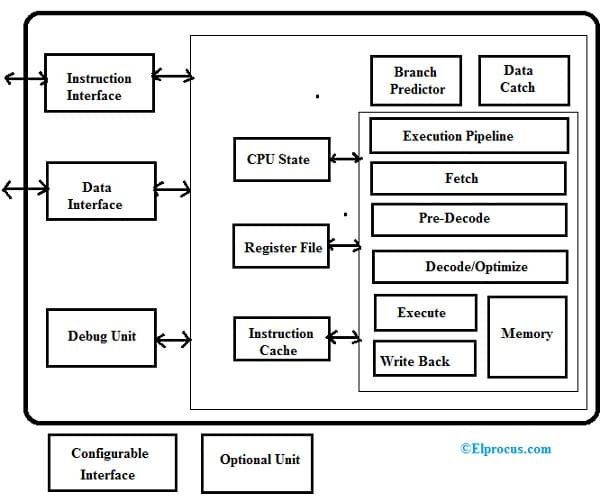
RV12 RISC V의 주요 기능은 다음과 같습니다.
- 산업 표준 명령어 세트입니다.
- 32비트 또는 64비트 데이터로 매개변수화됩니다.
- 정확하고 빠른 인터럽트가 있습니다.
- 사용자 지정 지침을 통해 독점 하드웨어 가속기를 추가할 수 있습니다.
- 단일 사이클 실행.
- 접힌 최적화가 있는 6단계 파이프라인.
- 메모리 보호 지원.
- 선택적 또는 매개변수화된 캐시.
- 극도로 매개변수화됨.
- 사용자는 32/64비트 데이터 및 분기 예측 단위를 선택할 수 있습니다.
- 사용자는 명령/데이터 캐시를 선택할 수 있습니다.
- 사용자가 선택할 수 있는 캐시의 구조, 크기 및 아키텍처.
- 사용자 정의 지연 시간에 따른 하드웨어 분배기 또는 승수 지원.
- 버스 아키텍처는 Wishbone & AHB를 지원하는 유연합니다.
- 이 디자인은 전력 및 크기를 최적화합니다.
- 디자인은 성능 또는 전력 트레이드오프를 제공하는 완전히 매개변수화됩니다.
- 전력을 감소시키는 게이트형 CLK 설계.
- 산업 표준에 따른 소프트웨어 지원.
- 건축 시뮬레이터.
- Eclipse IDE는 Linux/Windows용으로 사용됩니다.
RISC V 실행 파이프라인
여기에는 IF(명령 페치), ID(명령 디코딩), EX(실행), MEM(메모리 액세스) 및 WB(레지스터 쓰기 되돌림)와 같은 5단계가 포함됩니다.
명령어 가져오기
Instruction Fetch 또는 IF 단계에서는 프로그램 카운터(PC)와 다음 명령어로 업데이트되는 명령어 메모리에서 단일 명령어를 읽습니다.
명령어 사전 디코딩
RVC 지원이 허용되면 명령어 사전 디코딩 단계는 16비트 압축 명령어를 기본 32비트 명령어로 디코딩합니다.
명령어 디코딩
명령어 디코드(ID) 단계에서는 레지스터 파일이 허용되고 바이패스 제어가 결정됩니다.
실행하다
Execute 단계에서 ALU, DIV, MUL 명령어, Store 또는 Load 명령어에 허용된 메모리에 대한 결과가 계산되고 예상 결과에 대해 분기 및 점프가 측정됩니다.
메모리
이 메모리 단계에서 메모리는 파이프라인을 통해 액세스됩니다. 이 단계를 포함하면 파이프라인의 고성능이 보장됩니다.
다시 쓰기
이 단계에서는 실행 단계 결과가 레지스터 파일에 기록됩니다.
분기 예측자
이 프로세서는 RISC V 프로세서가 특정 분기를 선택했는지 여부를 결정할 때 안내하기 위해 과거 데이터를 저장하는 데 사용되는 분기 예측 장치 또는 BPU를 포함합니다. 이 예측 데이터는 분기가 실행되면 간단히 업데이트됩니다.
이 장치에는 동작을 결정하는 다양한 매개변수가 포함되어 있습니다. 예를 들어, HAS_BPU는 분기가 단위가 있을 것으로 예측하는지 여부를 결정하는 데 사용되며, BPU_GLOBAL_BITS는 몇 개의 과거 비트를 사용해야 하는지, BPU_LOCAL_BITS는 프로그램 카운터의 LSB 중 몇 개를 사용해야 하는지를 결정합니다. BPU_LOCAL_BITS & BPU_GLOBAL_BITS의 조합은 분기 예측 테이블을 처리하는 데 주로 사용되는 벡터를 생성합니다.
데이터 캐시
이것은 주로 새로 액세스한 메모리 위치를 버퍼링하여 데이터 메모리 액세스 속도를 높이는 데 사용됩니다. 자체 경계에 있는 경우 XLEN = 32일 때 하프워드, 바이트 및 워드 액세스를 처리할 수 있습니다. 자체 경계에 있는 경우 XLEN=64일 때 하프 워드, 바이트, 워드 및 더블 워드 액세스도 처리할 수 있습니다.
캐시 미스 동안 전체 블록을 메모리에 다시 쓸 수 있으므로 필요한 경우 새 블록을 캐시에 로드할 수 있습니다. DCACHE_SIZE를 0으로 설정하면 데이터 캐시가 비활성화됩니다. 그 후, 메모리 위치는 다음을 통해 직접 액세스됩니다. 데이터 인터페이스 .
명령어 캐시
이것은 주로 새로 페치된 명령어를 버퍼링하여 명령어 페치 속도를 높이는 데 사용됩니다. 이 캐시는 블록 경계가 아닌 16비트 경계에서 각 주기에 대해 하나의 구획을 가져오는 데 사용됩니다. 캐시 미스 동안 명령 메모리에서 전체 블록을 로드할 수 있습니다. 이 캐시의 구성은 사용자의 필요에 따라 수행할 수 있습니다. 캐시 크기, 대체 알고리즘 및 블록 길이를 구성할 수 있습니다.
ICACHE_SIZE를 0으로 설정하면 명령 주기가 비활성화됩니다. 그 후 소포는 메모리에서 직접 가져옵니다. 명령 인터페이스.
디버그 유닛
디버그 장치는 디버그 환경이 CPU를 중지하고 검사하도록 합니다. 이것의 주요 기능은 분기 추적, 최대 8개의 하드웨어 중단점까지 단일 단계 추적입니다.
파일 등록
이것은 X9 레지스터가 항상 0인 X0에서 X31까지 32개의 레지스터 위치로 설계되었습니다. 레지스터 파일에는 1-쓰기 포트 및 2-읽기 포트가 포함됩니다.
구성 가능한 인터페이스
이것은 이 프로세서가 다른 외부 버스 인터페이스를 지원하는 외부 인터페이스입니다.
RISC V는 어떻게 작동합니까?
RISC-V는 RISC(Reduced Instruction Set Computer) 원리에 기반을 둔 명령어 세트 아키텍처입니다. 이 프로세서는 하드웨어를 개발할 수 있고 소프트웨어를 이식할 수 있으며 프로세서가 이를 지원하도록 설계할 수 있는 무료 공용 오픈 소스 ISA이기 때문에 매우 독특하고 혁신적입니다.
차이점 B/W RISC V 대 MIPS
RISC V와 MIPS의 차이점은 다음과 같습니다.
|
RISC V |
MIPS |
| RISC V라는 용어는 'V'가 5세대인 Reduced Instruction Set Computer의 약자입니다. | 'MIPS'라는 용어는 'Million Instructions Per Second'를 의미합니다. |
| RISC-V를 사용하면 더 작은 장치 제조업체가 비용을 지불하지 않고 하드웨어를 설계할 수 있습니다. | MIPS를 사용하면 제조업체는 무료가 아니므로 지불하여 프로세서의 속도를 측정할 수 있습니다. |
| MIPS는 효율적으로 죽었습니다. | RISC-V는 효율적으로 죽지 않았습니다. |
| 이 프로세서는 두 레지스터를 비교하기 위한 분기 명령을 제공합니다. | MIPS는 대비가 참인지 여부에 따라 레지스터를 1 또는 0으로 찾는 비교 명령에 의존합니다. |
| ISA 인코딩 체계는 RISC V에서 고정 및 가변적입니다. | ISA 인코딩 체계는 MIPS에서 고정됩니다. |
| 명령어 세트 크기는 16비트 또는 32비트 또는 64비트 또는 128비트입니다. | 명령어 세트 크기는 32비트 또는 64비트입니다. |
| 32개의 범용 및 부동 소수점 레지스터가 있습니다. | 31개의 범용 및 부동 소수점 레지스터가 있습니다. |
| 26개의 단정밀도 및 배정밀도 부동 소수점 연산이 있습니다. | 15개의 단정밀도 및 배정밀도 부동 소수점 연산이 있습니다. |
차이점 B/W RISC V 대 ARM
RISC V와 ARM의 차이점은 다음과 같습니다.
|
RISC V |
팔 |
| RISC-V는 오픈 소스이므로 라이선스가 필요하지 않습니다. | ARM은 비공개 소스이므로 라이선스가 필요합니다. |
| 새로운 프로세서 플랫폼이므로 소프트웨어 및 프로그래밍 환경에 대한 지원이 매우 적습니다. | ARM은 마이크로프로세서, 마이크로컨트롤러 및 서버와 같은 다양한 플랫폼에서 대상 설계자를 지원하기 위해 라이브러리 및 구조를 지원하는 매우 큰 온라인 커뮤니티를 보유하고 있습니다. |
| RISC V 기반 칩은 1와트의 전력을 사용합니다. | ARM 기반 칩은 4와트 미만의 전력을 사용합니다. |
| 고정 및 가변 ISA 인코딩 시스템이 있습니다. | 고정 ISA 인코딩 시스템이 있습니다. |
| RISC V 명령어 세트 크기 범위는 16비트에서 128비트입니다. | 명령어 크기 범위는 16비트에서 64비트입니다. |
| 여기에는 32개의 범용 및 부동 소수점 레지스터가 포함됩니다. | 여기에는 31개의 범용 및 부동 소수점 레지스터가 포함됩니다. |
| 26개의 단정밀도 부동 소수점 연산이 있습니다. | 33개의 단정밀도 부동 소수점 연산이 있습니다. |
| 26배 정밀도 부동 소수점 연산이 있습니다. | 29배 정밀도 부동 소수점 연산이 있습니다. |
RISC V Verilog 코드
RISC용 명령어 메모리 Verilog 코드는 아래와 같습니다.
// RISC 프로세서용 Verilog 코드
// // 명령어 메모리용 Verilog 코드
모듈 Instruction_Memory(
입력[15:0] PC,
출력[15:0] 명령
);
reg [`col – 1:0] 메모리 [`row_i – 1:0];
와이어 [3 : 0] rom_addr = pc[4 : 1];
초기의
시작하다
$readmemb('./test/test.prog', 메모리,0,14);
끝
할당 명령 = 메모리[rom_addr];
엔드 모듈
16비트 RISC V 프로세서용 Verilog 코드:
모듈 Risc_16_bit(
입력 클럭
);
와이어 점프, bne, beq, mem_read, mem_write, alu_src, reg_dst, mem_to_reg, reg_write;
와이어[1:0] alu_op;
와이어 [3:0] opcode;
// 데이터 경로
데이터 경로_단위 DU
(
.clk(클크),
.점프(점프),
.개구리(개구리),
.mem_read(mem_read),
.mem_write(mem_write),
.alu_src(alu_src),
.reg_dst(reg_dst),
.mem_to_reg(mem_to_reg),
.reg_write(reg_write),
.bne(bne),
.alu_op(alu_op),
.opcode(opcode)
);
// 컨트롤 유닛
Control_단위 제어
(
.opcode(opcode),
.reg_dst(reg_dst),
.mem_to_reg(mem_to_reg),
.alu_op(alu_op),
.점프(점프),
.bne(bne),
.개구리(개구리),
.mem_read(mem_read),
.mem_write(mem_write),
.alu_src(alu_src),
.reg_write(reg_write)
);
엔드 모듈
명령어 세트
RISC V 명령어 세트는 아래에서 설명합니다.
산술 연산
RISC V 산술 연산은 다음과 같습니다.
| 니모닉 | 유형 | 지침 | 설명 |
| 추가 rd, rs1, rs2 |
아르 자형 |
추가하다 | rdß RS1 + RS2 |
| 서브 rd, rs1, rs2 |
아르 자형 |
덜다 | rdß rs1 – rs2 |
| 추가 rd, rs1, imm12 |
나 |
즉시 추가 | rdß rs1 + imm12 |
| SLT rd, rs1, rs2 |
아르 자형 |
미만으로 설정 | rdß rs1 -< rs2 |
| SLTI rd, rs1, imm12 |
나 |
즉시보다 적게 설정 | rdß rs1 -< imm12 |
| SLTU rd, rs1, rs2 |
아르 자형 |
unsigned보다 작게 설정 | rdß rs1 -< rs2 |
| SLTIU rd, rs1, imm12 |
나 |
즉시 unsigned보다 작게 설정 | rdß rs1 -< imm12 |
| 루이 rd, imm20 |
에 |
즉시 상단 로드 | rdß imm20<<12 |
| AUIP rd, imm20 |
에 |
PC에 즉시 상단 추가 | rdß PC+imm20<<12 |
논리 연산
RISC V 논리 연산은 다음과 같습니다.
| 니모닉 | 유형 | 지침 | 설명 |
| 그리고 rd, rs1, rs2 |
아르 자형 |
그리고 | rdß rs1 및 rs2 |
| 또는 rd, rs1, rs2 |
아르 자형 |
또는 | rdß RS1 | RS2 |
| XOR rd, rs1, rs2 |
아르 자형 |
무료 | rdß rs1 ^ rs2 |
| ANDI rd, rs1, imm12 |
나 |
그리고 즉시 | rdß rs1 및 imm2 |
| ORI rd, rs1, imm12 |
나 |
또는 즉시 | rdß RS1 | imm12 |
| OXRI rd, rs1, imm12 |
나 |
XOR 즉시 | rdß rs1 ^ rs2 |
| SLL rd, rs1, rs2 |
아르 자형 |
왼쪽으로 논리적으로 시프트 | rdß rs1 << rs2 |
| SRL rd, rs1, rs2 |
아르 자형 |
오른쪽 시프트 논리적 | rdß rs1 >> rs2 |
| RAS rd, rs1, rs2 |
아르 자형 |
오른쪽으로 시프트 산술 | rdß rs1 >> rs2 |
| SLLI rd, rs1, 샴트 |
나 |
왼쪽 논리적 즉시 시프트 | rdß rs1 << 샴트 |
| SRLI rd, rs1, 샴트 |
나 |
오른쪽으로 시프트 논리적 즉시 | rdß rs1 >> 샴트 |
| SRAI rd, rs1, 샴트 |
나 |
오른쪽으로 시프트 산술 즉시 | rdß rs1 >> 샴트 |
로드/저장 작업
RISC V 로드/저장 작업은 다음과 같습니다.
| 니모닉 | 유형 | 지침 | 설명 |
| LD rd, imm12(rs1) |
나 |
더블워드 로드 | rdß mem [rs1 +imm12] |
| LW rd, imm12(rs1) |
나 |
로드 워드 | rdß mem [rs1 +imm12] |
| LH rd, imm12(rs1) |
나 |
중간에 로드 | rdß mem [rs1 +imm12] |
| LB rd, imm12(rs1) |
나 |
로드 바이트 | rdß mem [rs1 +imm12] |
| LWU rd, imm12(rs1) |
나 |
부호 없는 단어 로드 | rdß mem [rs1 +imm12] |
| LHU rd, imm12(rs1) |
나 |
부호 없는 절반 단어 로드 | rdß mem [rs1 +imm12] |
| LBU rd, imm12(rs1) |
나 |
부호 없는 로드 바이트 | rdß mem [rs1 +imm12] |
| SD rs2, imm12(rs1) |
에스 |
더블 워드 저장 | rs2에서 mem으로 [rs1 + imm12] |
| SW RS2, imm12(rs1) |
에스 |
상점 단어 | rs2(31:0)에서 mem으로 [rs1 +imm12] |
| SH RS2, imm12(rs1) |
에스 |
중간에 저장 | rs2(15:0)에서 mem으로 [rs1 +imm12] |
| SB RS2, imm12(rs1) |
에스 |
저장 바이트 | rs2(15:0)에서 mem으로 [rs1 +imm12] |
| SRAI rd, rs1, 샴트 |
나 |
오른쪽으로 시프트 산술 즉시 | rs2(7:0)에서 mem으로 [rs1 +imm12] |
분기 작업
RISC V 분기 작업은 다음과 같습니다.
| 니모닉 | 유형 | 지침 | 설명 |
| BEQ rs1, rs2, imm12 |
SB |
분기 동일 | rs1== rs2인 경우 PC ß PC+imm12 |
| BNE rs1, rs2, imm12 |
SB |
분기가 같지 않음 | rs1!= rs2이면 PC ß PC+imm12 |
| BGE rs1, rs2, imm12 |
SB |
크거나 같은 분기 | rs1>= rs2인 경우 PC ß PC+imm12 |
| BGEU rs1, rs2, imm12 |
SB |
unsigned보다 크거나 같은 분기 | rs1>= rs2인 경우 PC ß PC+imm12 |
| BLT rs1, rs2, imm12 |
SB |
미만 지점 | rs1< rs2이면 PC ß PC+imm12 |
| BLTU rs1, rs2, imm12 |
SB |
서명되지 않은 분기 | rs1< rs2이면 PC ß PC+imm12 <<1 |
| JAL rd, imm20 |
UJ |
점프 및 링크 | rdßPC+4 PCß PC+imm20 |
| JALR rd, imm12(rs1) |
나 |
점프 및 링크 레지스터 | rdßPC+4 PCß rs1+imm12 |
장점
그만큼 RISC의 장점 V 프로세서 다음을 포함합니다.
- RISCV를 사용하여 개발 시간, 소프트웨어 개발, 검증 등을 절약할 수 있습니다.
- 이 프로세서는 단순성, 개방성, 모듈성, 깔끔한 디자인 및 확장성과 같은 많은 장점을 가지고 있습니다.
- 이것은 자유 소프트웨어 컴파일러인 GCC(GNU Compiler Collection)와 같은 여러 언어 컴파일러와 리눅스 OS .
- 로열티, 라이선스 비용 및 문자열 연결 없이 회사에서 자유롭게 사용할 수 있습니다.
- RISC-V 프로세서는 단순히 RISC의 확립된 원칙을 따르기 때문에 새롭거나 혁신적인 기능을 포함하지 않습니다.
- 다른 여러 ISA와 유사하게 이 프로세서 사양은 단순히 다양한 명령어 세트 수준을 정의합니다. 따라서 여기에는 32비트 및 64비트 변형과 부동 소수점 명령어를 지원하는 확장이 포함됩니다.
- 이들은 무료, 단순, 모듈식, 안정적 등입니다.
단점
그만큼 RISC V 프로세서의 단점 다음을 포함합니다.
- 컴파일러와 프로그래머는 복잡한 명령어를 자주 사용합니다.
- RISC의 o/p는 루프 내의 후속 명령어가 실행을 위한 이전 명령어에 의존할 때 코드를 기반으로 변경될 수 있습니다.
- 이러한 프로세서는 다양한 명령을 신속하게 저장해야 하며, 이를 위해서는 적시에 명령에 응답하기 위해 큰 캐시 메모리 세트가 필요합니다.
- RISC의 완전한 기능, 기능 및 이점은 주로 아키텍처에 따라 다릅니다.
애플리케이션
그만큼 RISC V의 응용 프로세서 다음을 포함합니다.
- RISC-V는 임베디드 시스템, 인공 지능 및 기계 학습에 사용됩니다.
- 이러한 프로세서는 고성능 기반 임베디드 시스템 애플리케이션에 사용됩니다.
- 이 프로세서는 엣지 컴퓨팅, AI 및 스토리지 애플리케이션과 같은 특정 분야에서 사용하기에 적합합니다.
- RISC-V는 소규모 장치 제조업체가 비용을 지불하지 않고 하드웨어를 설계할 수 있도록 하므로 중요합니다.
- 이 프로세서를 사용하면 연구원과 개발자가 자유롭게 사용 가능한 ISA 또는 명령어 세트 아키텍처를 사용하여 연구를 설계하고 연구할 수 있습니다.
- RISC V의 애플리케이션은 소형 임베디드 마이크로컨트롤러에서 데스크탑 PC 및 벡터 프로세서를 포함한 슈퍼컴퓨터에 이르기까지 다양합니다.
따라서 이것은 RISC V 프로세서 개요 – 아키텍처, 애플리케이션 작업. CISC 프로세서란 무엇입니까?